Secondo le best practices dei Linked Open Data, per pubblicare e collegare tra loro collezioni di dati strutturati attraverso il web, è necessario trasformare i dati secondo una struttura standard e un modello di dati specifico per il dominio di riferimento, attraverso una sintassi RDF e le ontologie.
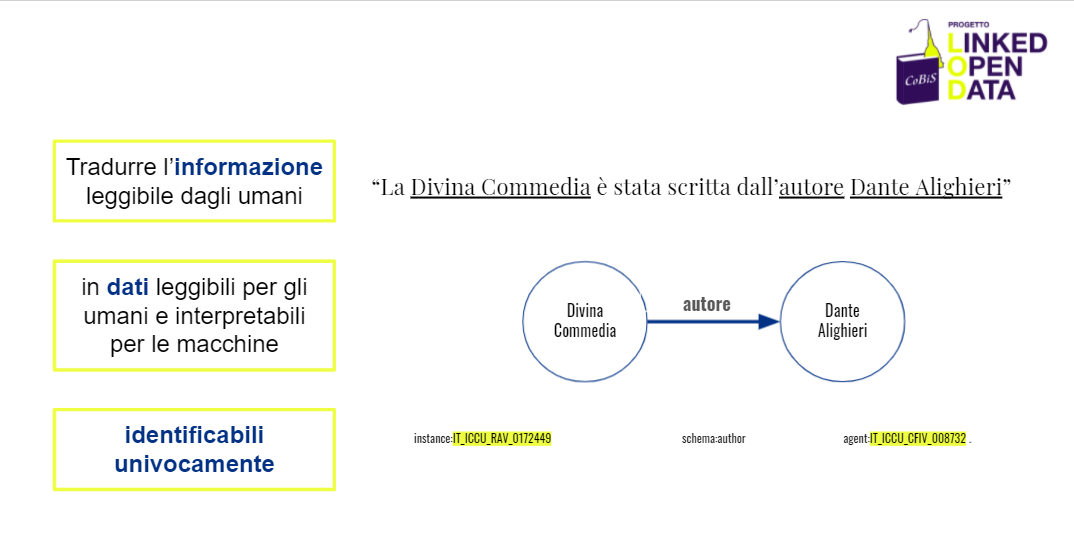 In questo modo, i dati non saranno più leggibili soltanto per gli umani, ma anche le macchine potranno interpretare il significato delle relazioni che intercorrono tra le risorse, identificate in modo univoco attraverso un codice a cui sono associate (come mostra la figura).
In questo modo, i dati non saranno più leggibili soltanto per gli umani, ma anche le macchine potranno interpretare il significato delle relazioni che intercorrono tra le risorse, identificate in modo univoco attraverso un codice a cui sono associate (come mostra la figura).
Grazie alla struttura tripartita delle informazioni e l’associazione di etichette che stabiliscono a livello semantico il tipo di relazione, una macchina è in grado di capire il concetto secondo cui la risorsa Divina Commedia ha come autore Dante Alighieri.
Questi argomenti sono stati introdotti nell’articolo Semantic Web e Linked Open Data: cosa sono e perché sono efficaci, ma nello specifico cosa sono le ontologie? A cosa servono? quali sono quelle utilizzate per i dati CoBiS?
Cos’è un’ontologia e a cosa serve
Si tratta di modello concettuale per descrivere in modo strutturato e gerarchico i concetti di un dominio specifico della conoscenza e le relazioni che definiscono i rapporti tra le diverse entità.
Gli elementi principali di un’ontologia sono le: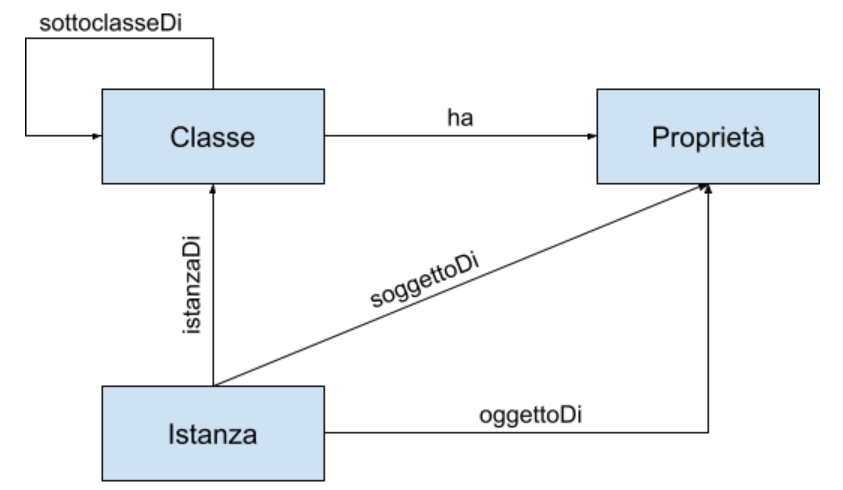
- classi, rappresentano i concetti generali del dominio di interesse da rappresentare;
- proprietà, definiscono il tipo di relazioni che intercorrono tra le classi;
- istanze, rappresentano oggetti del mondo reale che fanno parte di una determinata classe.
Ad esempio:
Divina Commedia istanzaDi Opera scritta . Opera scritta sottoclasseDi Opera .
Esistono diversi modelli per organizzare le informazioni in RDF, ma per rappresentare al meglio i dati e descrivere il tipo di relazione che lega gli elementi è necessario utilizzare un vocabolario specifico per il dominio di riferimento.
Dovendo rappresentare le informazioni di un catalogo in ambito bibliografico, ad esempio nel 2012 la Library of Congress ha pubblicato BIBFRAME, un’ontologia creata per favorire la trasformazione dei dati dal modello catalografico basato su MARC al Web semantico dei Linked Data.
In questo modo, i cataloghi delle biblioteche si diramano in una rete di entità individuate in maniera univoca e collegate tra loro da relazioni qualificate.
Le ontologie adottate per il CoBiS LOD
Il progetto Linked Open Data del CoBiS, che nel 2018 ha aggiornato il modello dei dati con l’ultima versione rilasciata dell’ontologia, è una delle prime iniziative in Italia ad aver adottato il modello BIBFRAME 2.0 e la prima a pubblicare un endpoint SPARQL organizzato secondo questa ontologia.
Rispetto alla prima versione, BIBFRAME 2.0 organizza le informazioni di una risorsa sulla base non di due, ma di tre livelli: Work, Instance e Item, livello aggiunto nella versione 2.0.
La descrizione bibliografica, quindi, si basa sul livello più astratto legato al concetto di opera, sul livello relativo a un’edizione, fino all’item ovvero la specifica copia posta sullo scaffale di una biblioteca.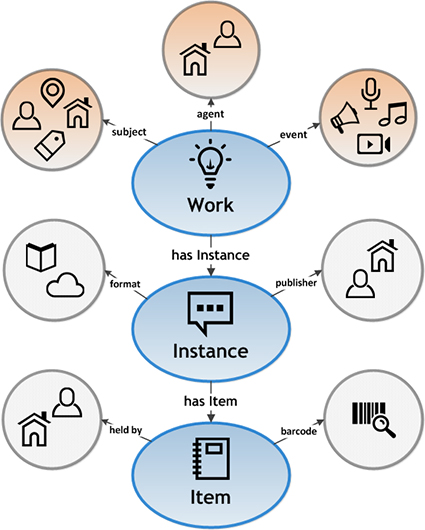
Queste classi sono collegate tramite proprietà alle altre informazioni relative, ad esempio, al titolo, autore, lingua, argomento, all’editore, luogo e data di pubblicazione.
Inoltre, l’ontologia definisce le relazioni tra queste 3 classi principali e le seguenti:
Agenti: persone, enti e organizzazioni collegate a un’opera o un’istanza da un ruolo specifico (come ad es. autore, compositore, editore).
Soggetti: i temi trattati nell’opera.
Eventi: può riferirsi ad es. alla fase di registrazione di un lavoro multimediale.
Questo modello consente di collegare gerarchicamente le tre classi principali (Opera, Istanza, Item) attraverso l’uso di specifiche proprietà che specificano le caratteristiche della risorsa da descrivere e la natura delle relazioni che le riguardano (ad esempio: un’opera può essere una traduzione di una specifica opera).
Oltre Bibframe, al fine di favorire l’interoperabilità semantica dei dati, sono state utilizzate proprietà di altre ontologie standard esistenti come Schema.org, RDFS, OWL, DCTerms, FOAF, Culturalis; inoltre, sono state inserite alcune proprietà custom per consentire la descrizione di dati specifici del nostro catalogo che non potevano essere rappresentati in modo efficace utilizzando le ontologie esistenti.
Ad esempio, è il caso di:
- cobis:bibliographicLevel, per descrivere la natura dell’edizione (monografia, periodico, spoglio, collana);
- cobis:bookType, per rappresentare la tipologia (testo a stampa, documento grafico, registrazione sonora musicale, risorsa elettronica, ecc.);
- cobis:hasWikidataURL, per collegare una specifica edizione del CoBiS al relativo elemento inserito su Wikidata con codice identificativo SBN.
Le informazioni bibliografiche sono pubblicate, secondo il modello RDF, sotto forma di triple concatenate e sono rappresentate da un identificativo univoco.
Per interrogarle è necessario utilizzare il linguaggio di interrogazione SPARQL, che si basa sul concetto di tripla e di grafo.
Se volessimo scoprire le proprietà utilizzate per descrivere una risorsa impostando una query tramite endpoint SPARQL, potremmo esplorare nello specifico le varie parti del modello ontologico.
Per impostare una query è necessario tradurre la domanda dal linguaggio naturale al linguaggio SPARQL, come si vedrà nel dettaglio nel prossimo articolo.
Per scoprire di più sul tema continuate a seguire il sito del CoBiS e i canali social.
A cura di Lianna D’Amato